My Tools

Python

MySQL

PostgreSQL

power BI

T-SQL

MS Fabric

R
Github
I'm Virginia Onchiri, a Data Analyst/Scientist and Machine Learning enthusiast. I enjoy turning raw, boring data into actionable insights and delivering solutions that enhance business growth. With hands-on experience in predictive modeling, and time-series forecasting, I've mastered the art of making data not sweat by making it work smarter.
As they say, all work and no play make Jane a dull girl. I have earned the (self-appointed) title of Undisputed Sudoku Champion among friends, family, and total strangers😁. I’m an avid reader of both fiction and non-fiction books. I’m also an almost professional swimmer.
Feel free to reach out to if you want to talk anything data or why I think “quizzify” is a valid word in scrabble.
Python
MySQL
PostgreSQL
power BI
T-SQL
MS Fabric
R
Github

Digital marketing campaigns are ubiquitous as organizations compete for their client's attention. In this project I explore the challenge of creating an effective marketing strategy in the context of banks. Using the data from the previously carried out marketing campaign and client information I build models to predict whether a client will subscribe to a term deposit or not in a future marketing campaign. Ultimately, the goal is to enable the marketing team to optimize their resources to reach out to those clients who have the highest likelihood to need and subscribe to the term deposit.

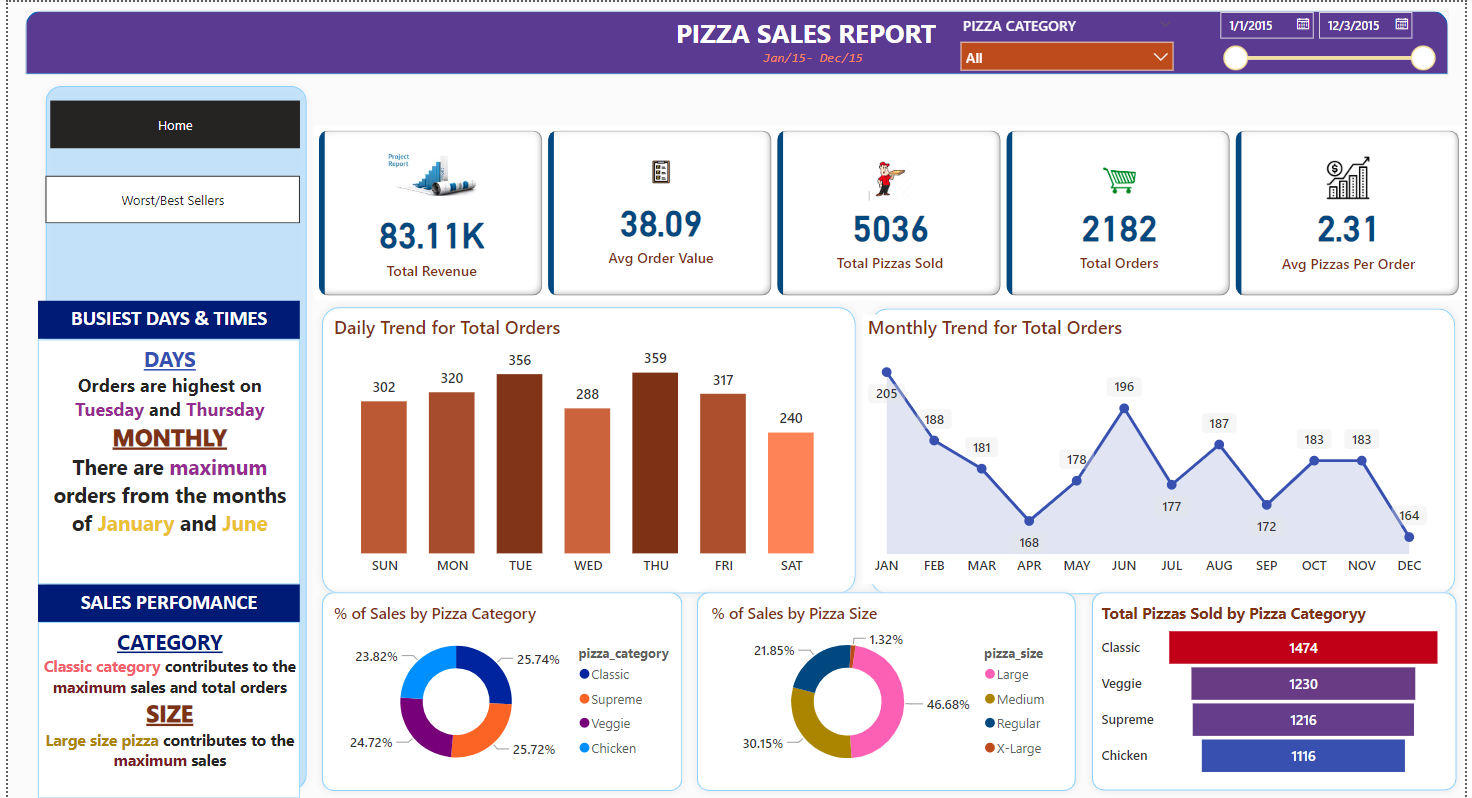
This project is an EDA for pizza sales to enable the business owners make informed decisions regarding the making of pizza. This EDA will enable them to know the best or the worst performing pizza according to revenue, total quantity, and total orders. It will also enable them to know during which months are the sales high and which pizza sizes sell more than others.

This project aims to predict the concentration of PM2.5, a key air pollutant, based on 23 environmental parameters. The study utilizes pollutant data from Taiwan’s Environmental Protection Administration. Crucial workflow steps, including data preprocessing, splitting into training and testing sets, and applying models are implemented. Ensemble, Gaussian Process Regression(GPR), Long Short-Term Memory (LSTM) with HMM, Long Short-Term Memory (LSTM), and Bayesian Ridge are applied to model and predict the possible concentration (PM2.5).
© Virginia Onchiri | All rights reserved.